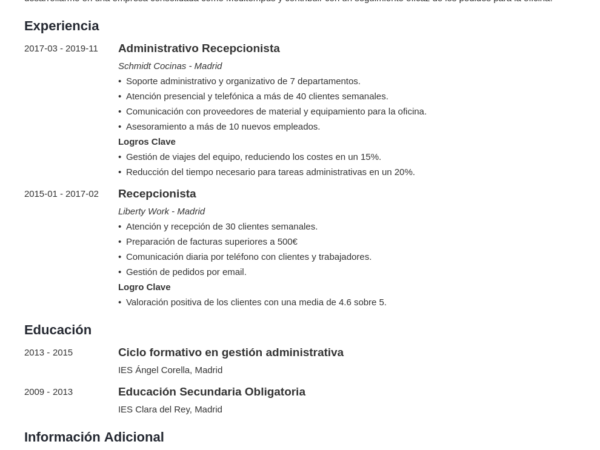
adminfebrero 22, 2024febrero 22, 2024 Secretos para Crear un Currículum Impresionante: Consejos y Estrategias
adminfebrero 22, 2024febrero 22, 2024 El Arte de la Personalización: Cómo Adaptar tu Currículum a Cada Oferta Laboral
adminfebrero 22, 2024febrero 22, 2024 El Poder de las Palabras: Optimiza tu Currículum con un Lenguaje Impactante